كيف يستطيع علم البيانات مساعدة الشركات في اختيار الموظفين؟
حالما يتم الإعلان عن توفر وظيفة معينة، تتراكم العشرات بل المئات من السير الذاتية، فلترة هذه السير لاختيار المناسب منها عملية شاقة ومكلفة، تُرى هل يستطيع علم البيانات مساعدة الموارد البشرية في حل هذه المشكلة؟ تعالوا نتعرف على حكاية Raman مع صديقه الباحث عن موظفين!
.
.
هذه تويتات قام بنشرها الدكتور حمود الدوسري على تويتر وقمنا بجمعها هنا للاستفادة من الموضوع

 بناء قاموس أو جدول يحتوي على مجموعة كلمات تمثل المهارات المطلوبةفي كل وظيفة
بناء قاموس أو جدول يحتوي على مجموعة كلمات تمثل المهارات المطلوبةفي كل وظيفة
 بناء خوارزمية NLP لمسح كل سيرة ذاتية للبحث عن الكلمات التي تم تعريفها في القاموس
بناء خوارزمية NLP لمسح كل سيرة ذاتية للبحث عن الكلمات التي تم تعريفها في القاموس
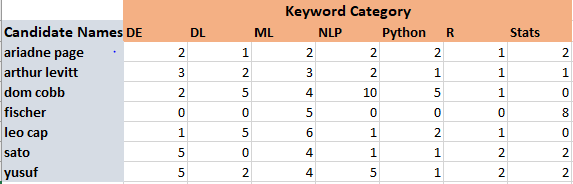
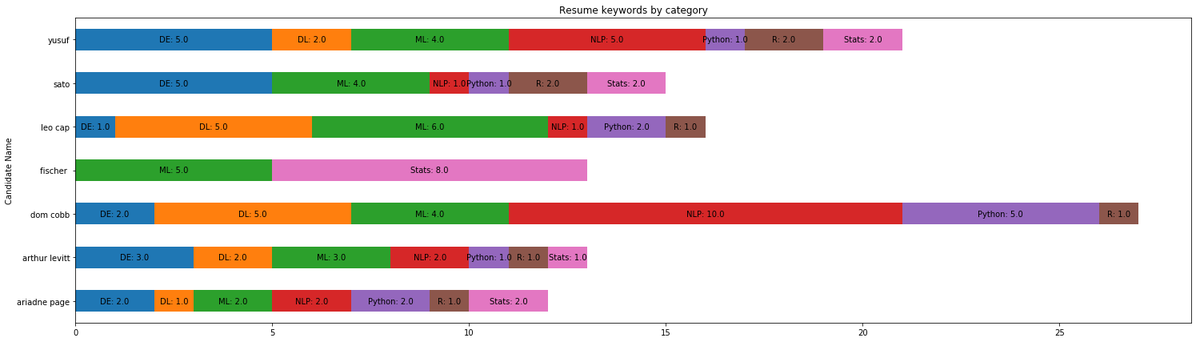
 حساب تكرار ظهور الكلمات في كل فئة لكل مترشح، كما في الجدول المرفق
حساب تكرار ظهور الكلمات في كل فئة لكل مترشح، كما في الجدول المرفق 










{kind=link}
التعليقآت